
Kilka tygodni temu komentowałem testy odporności systemów transakcyjnych, prezentowane w magazynie „Currency Trader”, a teraz się okazuje, że ich autor dorzucił we wrześniowym wydaniu posłowie, które okazało się małym trzęsieniem ziemi.
Przypomnę: chodziło o badanie tego na ile zakres danych użytych w testach ma wpływ na efektywność systemu transakcyjnego. Daniel Fernandez udowadniał w serii eksperymentów na przykładowej parze EUR/USD, że jedynie jak najdłuższe okresy danych użytych do stworzenia systemu transakcyjnego oraz jak najdłuższe okresy danych nie widzianych wcześniej, a służących weryfikacji, dają najbardziej wiarygodne i optymalne pod kilkoma względami rezultaty oraz podwyższają stabilność ostatecznego wyboru systemu.
Do przeczytania lub przypomnienia tutaj:
https://blogi.bossa.pl/2013/08/09/testy-trwalosci-systemow-transakcyjnych/
https://blogi.bossa.pl/2013/08/13/testy-trwalosci-systemow-transakcyjnych-czesc-2/
https://blogi.bossa.pl/2013/08/16/testy-trwalosci-systemow-transakcyjnych-czesc-3/
We wrześniowym numerze autor serwuje nam niezły suspens. Okazuje się, że każdy z rynków walutowych ma swoją „pamięć”, charakterystykę i unikalne cechy, co powoduje, że kryterium wyboru długich okresów to zbyt wąskie podejście, które może spowodować, iż ucieknie nam prawdziwa okazja. Postaram się jak najkrócej wyjaśnić dlaczego.
Nowa seria testów obejmowała tym razem rynki: USD/JPY oraz GBP/USD, a ich założenia wyglądały następująco:
1. Autor użył swojego autorskiego programu o nazwie „Kantu”, który służy do wykrywania systemów transakcyjnych w oparciu o powtarzające się zależności pomiędzy cenami, tworząc na ich podstawie algorytmy tradingowe.
2. Testowe dane dzienne obejmowały okres styczeń 1986- sierpień 2012
3. Zakres danych służących do tworzenia systemów (in-sample) obejmował zbiory od 500 do 5500 dni.
4. Zakres danych służących do weryfikacji systemów (out-of-sample) obejmował zbiory od 200 do 800 dni.
5. W teście in-sample generowane zostało za każdym razem 1 000 systemów, których wyniki były dodatnie a dla których współczynnik determinacji (R2) wyniósł 0,9. Ponieważ ten wymóg formalny spełniało dużo mniej systemów niż dla pary EUR/USD dlatego wyników wyszło sporo mniej do analizy.
Przykładowy, pojedynczy test wyglądał następująco:
Dla danych in-sample z 2000 dni (np. okres 1 sierpnia 2000 do 22 czerwca 2006) generowano 1000 wspomnianych wyżej systemów, po czym sprawdzano ich działanie na kolejnej próbce danych out-of-sample z np. 200 dni (za okres 23 czerwca 2006 do 11 sierpnia 2006).
Zaskoczenie natomiast polega na tym, że wyniki końcowe ułożyły się w całkiem zaskakujący i zarazem odmienny wzór niż w przypadku eksperymentów z parą EUR/USD. Pokażę to na przykładzie przeżywalności systemów puszczonych na próbce danych nie widzianych przy tworzeniu:
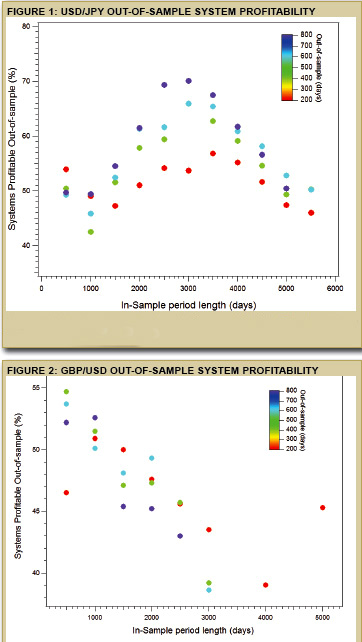
Żródło: Currency Trader sierpień 2013
Na skali poziomej w obu przypadkach mamy ilość dni, użytych w danych in-sample (czyli tych do zbudowania systemu). Do testowania za każdym razem pobierano ich o 500 więcej.
Skala pionowa pokazuje odsetek tych, które PRZEŻYŁY ZYSKOWNIE próbę na nowych danych out-of-sample.
Poszczególnymi kolorami kropek oznaczono zbiory danych out-of-sample.
Co oznaczają owe wyniki?
Para USD/JPY
Szanse przeżycia rosną wraz z ilością dni użytych do budowy systemu ale TYLKO gdy nie będzie ich więcej niż 3000, potem natomiast skuteczność opada. To samo dotyczy ilości dni służących weryfikacji. W najlepszym przypadku, czyli danych in-sample z 3000 dni, istnieje szansa, że niemal 70% z systemów przeżyje w teście na ”nie widzianych” wcześniej danych z 800 dni.
Para GBP/USD
Tutaj wzorzec zachowania wygląda kompletnie przeciwnie niż dla EUR/USD! Szanse przeżycia drastycznie maleją wraz z ilością dni użytych do budowy systemu! Co ciekawe również wydłużanie zbiorów dni służących jego weryfikacji wypada w sumie najgorzej. W najlepszym przypadku, czyli danych in-sample z 500 dni, istnieje szansa, że niemal 55% z systemów przeżyje w teście na ”nie widzianych” wcześniej danych z 400 dni. Ale już testy powyżej 1500 dni wypadają gorzej niż losowy rzut monetą!
Identyczny niemal rozkład dla obu par wyszedł w teście badającym średni zysk (średnią stratę) w sytuacji gdy wchodzimy w transakcje wszystkimi 1000 systemami jednocześnie. Przy czym najbardziej obiecujące pod względem zyskowności okazały się systemy na parę USD/JPY – maksimum 10$ zysku dziennie (GBP/USD tylko 4$ a wcześniej EUR/USD 6$).
Wnioski:
Niestety każdy rynek należy w budowie i testach systemów traktować odrębnie i nie ekstrapolować wniosków na pozostałe. Szczególnie dotyczy to Walk Forward Tests, w których stoimy przed koniecznością wyboru okresów do budowy i weryfikacji, co wbrew pozorom ma ogromne znaczenie dla wykrycia i stabilności przewagi.
I tak jak dla pary EUR/USD im dłuższy okres danych użytych do ich budowy i weryfikacji tym szanse przeżycia większe. To pozornie oczywiste ponieważ system ma wówczas szansę „zobaczyć” wszelkiego rodzaje warunki rynkowe – hossy, bessy i flauty o różnych zmiennościach. Ale takie podejście kompletnie nie wydobędzie przewagi z danych GBP/USD! Wymagają one innego traktowania. Stąd wniosek, że zakresy danych służących do projektowania systemów nie mogą być statyczne lecz dla każdego rynku zmienne i szczegółowo analizowane.
Jak się okazuje również, „pamięć” rynków zawarta w danych nie ma jednorodnego charakteru. Oto bowiem dla pary GBP/USD używanie do budowy danych z więcej niż 1000 dni mija się z celem. A co to z kolei oznacza? Nic innego jak konieczność częstych optymalizacji parametrów. Istnieje bowiem spore prawdopodobieństwo, że parametry wyciągnięte z danych dłuższych niż 1000 dni szybko się zdeaktualizują. W przeciwieństwie do rynku EUR/USD gdzie im więcej danych zaciągniemy tym „pamięć” o tym co działo się w przeszłości pozostaje trwalsza.
—kat—

11 Komentarzy
Dodaj komentarz
Niezależnie, DM BOŚ S.A. zwraca uwagę, że inwestowanie w instrumenty finansowe wiąże się z ryzykiem utraty części lub całości zainwestowanych środków. Podjęcie decyzji inwestycyjnej powinno nastąpić po pełnym zrozumieniu potencjalnych ryzyk i korzyści związanych z danym instrumentem finansowym oraz rodzajem transakcji. Indywidualna stopa zwrotu klienta nie jest tożsama z wynikiem inwestycyjnym danego instrumentu finansowego i jest uzależniona od dnia nabycia i sprzedaży konkretnego instrumentu finansowego oraz od poziomu pobranych opłat i poniesionych kosztów. Opodatkowanie dochodów z inwestycji zależy od indywidualnej sytuacji każdego klienta i może ulec zmianie w przyszłości. W przypadku gdy materiał zawiera wyniki osiągnięte w przeszłości, to nie należy ich traktować jako pewnego wskaźnika na przyszłość. W przypadku gdy materiał zawiera wzmiankę lub odniesienie do symulacji wyników osiągniętych w przeszłości, to nie należy ich traktować jako pewnego wskaźnika przyszłych wyników. Więcej informacji o instrumentach finansowych i ryzyku z nimi związanym znajduje się w serwisie bossa.pl w części MIFID: Materiały informacyjne MiFID -> Ogólny opis istoty instrumentów finansowych oraz ryzyka związanego z inwestowaniem w instrumenty finansowe.
Jesli na skorelowanych rynkach (gbp eur / usd) nie mamy skorelowanych wynikow to caly system jest do doopy.
Fajnie, że się gość zreflaktował bo poprzednich testach można było odniesc wrażenie , że im dłuższy termin tym sukces 100%.
Atu zonk co mnie cieszy bo jest bardziej zgodne z oglądem który mnie przekonuje.
@Lucky
te skorelowane wyniki to ciężko uzyskac bo co prawda do tego autor jeszcze nie doszedł ale róznica typu byc albo nie być jest nawet na tej samej parze z danych od różnych brokerów.
Edge maszynowy jest to bardzo fragile i ulotna rzecz. Podejście typu quantity trading skutkuje często 5 krokami do przodu i 4 do tyłu więc łatwo ten jeden kroczek zaprzepaścić nawet kilkoma pipsami róznicy .
Chwała Bogu! Jesteśmy uratowani! Kwiaty dla prezesa Maciejewskiego.
Para USD/JPY + Para GBP/USD itp itd
Czyżby cała para poszła w gwizdek? 🙂
A ja czekałbym na ciąg dalszy w formie tego: jak z 1000, z których przeżywa 70%, wybrać ten 1-2 czy nawet kilka 🙂
Myślę, że można puścić mail z pytaniami do Currency Tradera lub Fernandeza, zawsze odpowiadali na sensowne pytania. Gdyby ktoś chciał dołożyć jakieś – dajcie cynk tutaj lub na kathay () bossa pl
Jesli na jednej parze potrzeba wiekszego okresu i on dziala dobrze w przod, a na drugiej dlugi okres dziala dobrze w tyl ale zle w przod, to znaczy, ze cale proces naszego wnioskowania statystycznego jest OKDR i nie powinnismy wyciagac zadnych wnioskow na podstawie przeszlosci.
Tak, dopóki, dopóty zakres danych nie będzie uwzględniał auxilium cykli planetarnych, będziemy błądzić i będziemy olśnieni doświadczeniem błędu, będziemy błądzić i będziemy oblewani olśnieniem…
Tu panowie rację ma Lucky.
@Lucky
Problem w tym, że na podstawie (między innymi) Walk Forward Tests jakieś wnioski musimy wyciągnąć i lepiej mniej niepoprawne niż niepoprawne bardziej 🙂
Powiedzcie mi jaki ma sens przewidywanie czegoś i tworzenie sytemów i strategii, jeśli po drugiej stronie są ci z kasą co grają to co widzą. Bez sensu, oni widza pozycje i wszelkie lim/stop itp i rzeczywistość est tworzona na bieżąco, wiec zaden system nic nie da.
Model biznesu jest prosty – drobnica traci, my zarabiamy. Az zrodelko wyschnie a my juz zainwestujemy w inne branze.
@Exnergy, to niezbyt dobry krok aby bardzo heterogeniczną grupę przedstawiać rozdziałem my-oni.
To są różnej wielkości jednostki, o różnej wiedzy, różnym doświadczeniu i kapitale, różnych modelach biznesu. Nie było jednego planu sprawczego, który na samym początku, u zarania branży finansowej, został kolektywnie ustalony, przez „onych”, wpływową burżuazję, która przerodziła się w sektor finansowy.
To jest coś, co powstało od dołu. Na rynkach są teraz wszyscy: oni-my-tamci-tamte-owante. Podsektory-podsektorów. Konflikt interesów ma miejsce na poziomie indywidualnych jednostnek. Nie ma co uciekać w teorie spiskowe, niepotrzebnie, bo ludzie łatwo wierza w takie banialuki i potem mamy takich a nie innych włodarzy. My obserwujemy samo kręcące się koło napędzane systemem bodźców z jednej strony, zaś informacją/przypadkiem z drugiej. That’s it.