
I ostatni z testów stabilności mechanicznych systemów tradingowych, zaczerpnięty ponownie z artykułu D.Fernandeza, omawianego w poprzednich dwóch wpisach.
TEST 3. ZYSKOWNOŚĆ
Ma odpowiedzieć na pytanie jakiej średniej zyskowności można oczekiwać w teście systemów na różnej długości danych nie widzianych przy ich konstrukcji. Przy czym miarą zyskowności jest średni profit w dolarach w przeliczeniu na dzień.
Szybkie przypomnienie warunków testów:
– generowane i weryfikowane było 5 000 systemów transakcyjnych opartych na zależnościach między cenami,
– użyto dziennych kursów historycznych pary EUR/USD za okres styczeń 1986- sierpień 2012
– zakres danych in-sample (użytych do budowy systemu) obejmował stopniowo od 500 do 5000 dni (co 500)
– zakres danych weryfikacyjnych czyli out-of-sample (nie widzianych przez system przy jego tworzeniu) obejmował stopniowo od 200 do 800 dni
Tradycyjnie zbiorczy rezultat testów w formie wizualizacji graficznej poniżej:
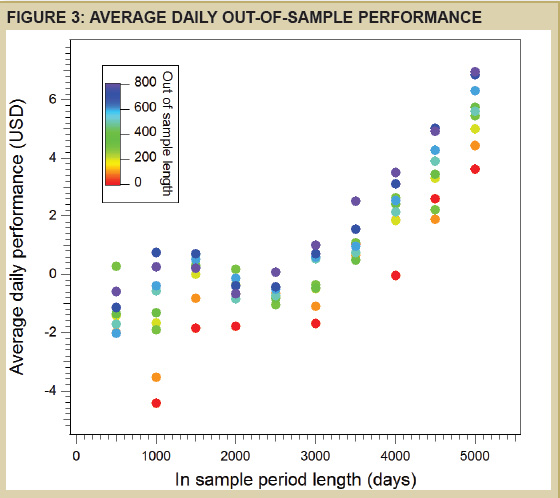
źródło: Currency Trader sierpień 2013
Skala pozioma pokazuje ilość dni użytych w danych in-sample (czyli tych do zbudowania systemu).
Skala pionowa pokazuje ŚREDNI DZIENNY ZYSK/STRATĘ WSZYSTKICH 5000 SYSTEMÓW na danych out-of-sample (nie widzianych wcześniej).
Poszczególnymi kolorami oznaczono dla orientacji zbiory danych out-of-sample.
Dla prawidłowego wnioskowania ważne jest zrozumienie założenia tego testu: poszczególne punkty powyższego wykresu pokazują średni zysk/stratę w sytuacji gdy wchodzimy w transakcje wszystkimi 5000 systemami. Mamy więc jedynie średni, statystyczny wynik całości z nich, ale nawet w grupie pokazującej stratę mogą istnieć systemy posiadające przewagę czyli generujące zyski.
Co widać na wykresie:
W zasadzie niemal wszystkie grupy systemów układane w oparciu o dane z mniej niż 3000 dni generują średnio straty. Im jednak dłuższy okres danych in-sample i out-of-sample tym wyższe zyski, sięgające w najlepszym wypadku średnio 6 USD/dzień.
Ponownie jak poprzednio przewaga statystyczna (pozytywna wartość oczekiwana) systemów daje się poznać dopiero wówczas gdy do obu testów (in-sample i out-of-sample) użyjemy jak najszerszych zakresów danych. Widać to po coraz wyżej położonych kropkach gdy przesuwamy się w prawo po wykresie. Algorytmy mają wówczas bowiem okazję poznać dużo bardziej zróżnicowane środowisko działania pod względem zmienności i trendów. Eliminujemy więc część przypadkowości z całego procesu a szansa przeżycia systemu rośnie.
Biorąc pod uwagę wszystkie 3 przytoczone przez mnie eksperymenty można wysnuć pewien ogólny i dość oczywisty wniosek odnośnie podziału zbioru danych do testów:
Proporcjonalnie jak najdłuższy okres danych użytych przy (a) konstrukcji systemów jak i (b) nie widzianych przy budowie jest pożądany do osiągnięcia jak najbardziej wiarygodnych rezultatów i wydobycia realnej, rzeczywistej przewagi statystycznej.
Wniosek kolejny nie pada już w artykule, ale nie sposób nie zwrócić na niego uwagi:
Bardzo istotną sprawą jest maksymalne wydłużenie danych użytych podczas tzw. Walk Forward Test (test kroczący). Zbyt krótkie przedziały danych zarówno in-sample jak i out-of-sample mogą przynieść mocno mylące wyniki, nie oddające rzeczywistej przewagi tkwiącej w systemach. Wszystkie 3 przywołane wykresy pokazały to nadwyraz dobitnie.
—kat—

1 Komentarz
Dodaj komentarz
Niezależnie, DM BOŚ S.A. zwraca uwagę, że inwestowanie w instrumenty finansowe wiąże się z ryzykiem utraty części lub całości zainwestowanych środków. Podjęcie decyzji inwestycyjnej powinno nastąpić po pełnym zrozumieniu potencjalnych ryzyk i korzyści związanych z danym instrumentem finansowym oraz rodzajem transakcji. Indywidualna stopa zwrotu klienta nie jest tożsama z wynikiem inwestycyjnym danego instrumentu finansowego i jest uzależniona od dnia nabycia i sprzedaży konkretnego instrumentu finansowego oraz od poziomu pobranych opłat i poniesionych kosztów. Opodatkowanie dochodów z inwestycji zależy od indywidualnej sytuacji każdego klienta i może ulec zmianie w przyszłości. W przypadku gdy materiał zawiera wyniki osiągnięte w przeszłości, to nie należy ich traktować jako pewnego wskaźnika na przyszłość. W przypadku gdy materiał zawiera wzmiankę lub odniesienie do symulacji wyników osiągniętych w przeszłości, to nie należy ich traktować jako pewnego wskaźnika przyszłych wyników. Więcej informacji o instrumentach finansowych i ryzyku z nimi związanym znajduje się w serwisie bossa.pl w części MIFID: Materiały informacyjne MiFID -> Ogólny opis istoty instrumentów finansowych oraz ryzyka związanego z inwestowaniem w instrumenty finansowe.
6 USD dziennie to z transakcji jednym lotem?