
Na ile zakres danych użytych w testach ma wpływ na efektywność systemu transakcyjnego? Temu mam zamiar przyglądnąć się niżej.
Źródłem będzie tym razem artykuł zaczerpnięty z sierpniowego numeru „Currency Trader”, autorstwa Daniela Fernandeza, który dość regularnie publikuje tam pomysły na strategie/systemy oraz dzieli się swoją wiedzą na temat efektywności mechanicznego podejścia. Niezwykle inspirujący i wart prezentacji wydał mi się problem znaczenia okresów testowych, solidnie statystycznie i wizualnie udokumentowany przez niego i zamieszczony pod tytułem „FX trading system development: Outperforming your test”.
Zacznę jednak od tego, że w prezentowanych testach użył on stworzonego przez siebie programu o nazwie „Kantu”, który służy do mechanicznej budowy lub może raczej wykrywania systemów transakcyjnych. Fernandez nie robi jednak przy tym żadnej nachalnej reklamy więc i ja bym nie chciał, ale dla zrozumienia tematu potrzebne jest mini wprowadzenie w tym zakresie.
Otóż zadaniem „Kantu” (dość łatwo znaleźć go w wyszukiwarce) jest automatyczne tworzenie systemów opartych wyłącznie o układy cenowe, znalezione w załadowanych do niego danych. Po ustawieniu własnego zakresu udostępnionych software’owo kryteriów program przeszukuje dane, wykrywając powtarzające się w nich zależności pomiędzy cenami, tworząc na tej podstawie algorytmy dające się dalej testować na danych nie widzianych w testach i tworząc bazę potencjalnie najbardziej skutecznych rozwiązań do tradingu w sposób mechaniczny w przyszłości.
Przy okazji znalazłem darmowego e-booka stworzonego przez Fernandeza, a traktującego o tradingu systemowym na rynku forex (niestety tylko po angielsku). Muszę przyznać, że dość w przystępny sposób wyjaśnia tam problemy mogące powstawać podczas zabaw z systemami. Tym razem bez kozery podam adres, pod którym można go znaleźć:
http://entirely4you.com/free_ebook.pdf
I przy użyciu „Kantu” autor dokonuje testów oraz obudowuje je opisem trzech kategorii eksperymentów, w których pokazuje zależności pomiędzy okresem danych użytych do budowy systemu (tzw. in-sample) i danych sprawdzających skuteczność, które nie były widziane podczas budowania (tzw. out-of-sample).
Założenia początkowe wyglądały we wszystkich trzech przypadkach jednakowo:
1. Dane dzienne pary EUR/USD zostały użyte, okres styczeń 1986- sierpień 2012
2. Zakres danych in-sample obejmował stopniowo od 500 do 5000 dni
3. Zakres danych out-of-sample obejmował stopniowo od 200 do 800 dni
4. W teście in-sample generowane zostało za każdym razem 5 000 systemów opartych na zależnościach cenowych, których wyniki były dodatnie a dla których współczynnik determinacji (R2) wyniósł 0,9.
Przykładowy, pojedynczy test wyglądał następująco:
Dla danych in-sample z 2 000 dni (np. okres 1 sierpnia 2000 do 22 czerwca 2006) generowano 5 000 wspomnianych wyżej systemów, po czym sprawdzano ich działanie na kolejnej próbce danych out-of-sample z np. 200 dni (za okres 23 czerwca 2006 do 11 sierpnia 2006).
TEST 1. PRZEŻYWALNOŚĆ
Miał on odpowiedzieć na pytanie ile procent wygenerowanych systemów przeżyło zyskownie jeśli puszczono je na „nie widzianych” wcześniej przez nich danych. Inaczej rzecz ujmując: taka symulacja odpowiada na pytanie jaka szacunkowo część utworzonych systemów mechanicznych daje sobie teoretycznie radę w realnym tradingu. Wyniki pokazuje poniższy diagram zaczerpnięty z artykułu:
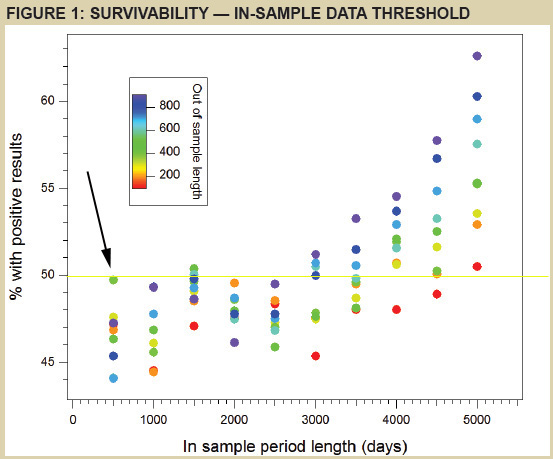
Żródło: Currency Trader sierpień 2013
Jak go czytać:
Na skali poziomej mamy ilość dni, użytych w danych in-sample (czyli tych do zbudowania systemu). Do testowania za każdym razem pobierano ich o 500 więcej.
Skala pionowa pokazuje odsetek tych, które przeżyły zyskownie próbę na nowych danych out-of-sample.
Poszczególnymi kolorami oznaczono dość płynnie właśnie zbiory danych out-of-sample.
I tak np. wskazana przez mnie strzałką zielona kropka oznacza, że spośród 5000 zyskownych systemów ułożonych na podstawie danych z 500 dni przeżyło średnio niecałe 50% z nich puszczone dla sprawdzenia na zbiorze ok. 400 kolejnych dni.
Ową granicę 50% zaznaczyłem na wykresie również – za pomocą poziomej, żółtej linii. Jak widać niemal wszystkie systemy układane na zbiorze danych obejmujących mniej niż 3000 dni nie przekroczyły owego poziomu. Co prowadzi do wniosku, że najwyżej co drugi z nich przeżywa test na danych nie widzianych przy jego konstrukcji. Mamy więc do czynienia z szansami nieco gorszymi niż na poziomie losowości (jak w rzucie monetą).
Szanse przeżycia rosną wraz z ilością dni użytych do budowy systemu. W najlepszym przypadku- czyli danych z 5000 dni – istnieje szansa, że niemal 65% z systemów przeżyje w teście na ”nie widzianych” wcześniej danych z 800 lub więcej dni (kropka granatowa położona najwyżej).
Co to oznacza?
Można wyciągnąć jakieś przybliżone wnioski, ale tylko odnośnie wszystkich systemów budowanych w oparciu jedynie o ceny (układy świecowe, kanały cenowe, klasyczne formacje techniczne, wsparcia/opory itp.). Im większy okres danych użytych do ich budowy tym szanse przeżycia większe. To oczywiste ponieważ system podczas tworzenia ma szansę „zobaczyć” wszelkiego rodzaje warunki rynkowe – hossy, bessy i flauty o różnych zmiennościach.
Po drugie – im testy na dłuższych ciągach danych nie widzianych przy budowie (out-of-sample) tym większa szansa, że system przeżyje (proszę zobaczyć to po kolorach kropek dla tych testów powyżej 3000 dni). Po prostu jeśli system posiada rzeczywistą przewagę statystyczną to łatwiej ją wykazać potem w dłuższym okresie na nowych danych. Okresy krótkie często łapać mogą bowiem w teście out-of-sample tylko obsunięcia systemu, okresy dłuższe uwzględniać powinny również warunki sprzyjające (tzw. run-ups).
CDN
—kat—

18 Komentarzy
Dodaj komentarz
Niezależnie, DM BOŚ S.A. zwraca uwagę, że inwestowanie w instrumenty finansowe wiąże się z ryzykiem utraty części lub całości zainwestowanych środków. Podjęcie decyzji inwestycyjnej powinno nastąpić po pełnym zrozumieniu potencjalnych ryzyk i korzyści związanych z danym instrumentem finansowym oraz rodzajem transakcji. Indywidualna stopa zwrotu klienta nie jest tożsama z wynikiem inwestycyjnym danego instrumentu finansowego i jest uzależniona od dnia nabycia i sprzedaży konkretnego instrumentu finansowego oraz od poziomu pobranych opłat i poniesionych kosztów. Opodatkowanie dochodów z inwestycji zależy od indywidualnej sytuacji każdego klienta i może ulec zmianie w przyszłości. W przypadku gdy materiał zawiera wyniki osiągnięte w przeszłości, to nie należy ich traktować jako pewnego wskaźnika na przyszłość. W przypadku gdy materiał zawiera wzmiankę lub odniesienie do symulacji wyników osiągniętych w przeszłości, to nie należy ich traktować jako pewnego wskaźnika przyszłych wyników. Więcej informacji o instrumentach finansowych i ryzyku z nimi związanym znajduje się w serwisie bossa.pl w części MIFID: Materiały informacyjne MiFID -> Ogólny opis istoty instrumentów finansowych oraz ryzyka związanego z inwestowaniem w instrumenty finansowe.
Wieksza przyzywalnosc systemow z dlugim okresem oos wynika z tego, ze systemy maja rzeczywista przewage a nie sa zbiegiem okolicznosci. Po prostu dla dobrego systemu czas dziala na jego korzysc, dla kiepskiego dziala na niekorzysc (ze wzgledu na prowizje). Ja sprawdzam to w ten sposob (przykladowe dane):
Test na 1 roku – srednio 59% rynkow zystkownych
Test na 5 latach – srednio 72% rynkow zyskownych
Test na 10 latach – srednio 81 % rynkow zyskownych
Test na 20 latach – srednio 100% rynkow zyskownych
Ja sie nie znam, więc zapytam tak naiwnie: czy to znaczy, że przetestowany na odpowiedniej ilości danych system ma szanse poradzić sobie ze zmianą W20 na W30? 🙂
@_dorota:
Mysle, ze dobry system bedzie dzialal na tych samych parametrach na w20, w30, euro i aapl.
@_dorota
Poradzic to on może sobie może poradzić tylko to nie jest profesjonalne podejście tylko dziecinada, hazard itp.
Po to sie go tuninguje , że się tak wyrażę by znac jego parametry typu CAGR, DD itp. i na tej podstawie określić ryzyko czyli stawkę , którą gramy.
JEżeli mam to określone np. gram taka stawką by w okresie roku nie przekroczyć 10% DD to jest wykluczne bym zagrał tylko dlatego ,że mam dobry system z nadzieją ,że sobie poradzi.
Jak sobie poradzi bo parametry sie zmieniły na tyle ,że będę miał po roku np. 3 razy większy DD i połowę mniejszy zysk no to ja dziękuję za takie poradzenie sobie.
To jest dobre do jakiś teoretycznych rozważań na blogu , ale nie do produkcji.
Dlatego też mój głos w sprawie płynnego przejścia by w miarę bezpiecznie opuścić stare i naprawde dziwię się ,że tzw profesjonalizm osób tu piszących tego nie dostrzega natomiast widzę entuzjazm bo prezes im dał nową zabawkę do zabawy by se popykali dla sportu i jak jest punkcik razy dwadzieścia to cieszmy się bracia bo zyski wzrosną razy 2 .
Wystarczy wajchę przełożyc panie Majster- ot heurystyka na miarę bossablo.
NIe przeczę na danych tygodniowych czy mieśięcznych to może zmiany nie będzie, ale przecież nie o tym.
Ogólnie więc Żenada.
I żeby było jasne jestem za tylko nie w sposób jaki to robi Prezes.
Ten sposób jest właśnie robiony w kontekście pełnoprawnego kasyna.
@Lucky.
Myślisz czy wiesz?
Bo na tych samych parametrach to działa /przynajmniej teorytecznie/ jedynie rozkład normalny.Innego nie uwidił.
Osobiście myślę ,że dobry system na tych samych samych parametrach to zadziała dodatkowo też na marchewce , cebulce , ziemniaczkach i jeszcze je obierze do obiadu 😉
Serio jak ma byc taki dobry to niech będzię full service.
Życze szczęścia w poszukiwaniach Yeti. Podobno istnieje 🙂
„Test na 20 latach – srednio 100% rynkow zyskownych”
Podaj jakieś wyniki bo zalezność jest taka że im dłużej tym zyski przeciętnieją , a ryzyko nie za bardzo.
W końcu okaże się ,że za 5% rocznie trzeba podejmowac niewspółmierne ryzyko.
No ale jako rzekłeś 100% zyskowne więc nie dyskutuję.
I nie obraź się . Tak sobie gdybam z braku konkretów, z własnych obserwacji 🙂
@pit:
„Podaj jakies wyniki”: To sa wyniki mojego systemu podazania za trendem. Niestety o samym systemie za duzo dyskutowac nie bede. Oczywiscie za X okres dla Y rynku najlepszy parametr to np Z, ale im dluzszy okres wezmiemy do testow, tym wiekszy zakres parametrow przynosi zyski (po odjeciu prowizji).Tym sposobem mozna znalesc takie parametry, ktore dzialaly na dosc szerokim zakresie dat i rynkow, dzieki czemu czuje sie pewniej uzywajac takiego systemu. (Tu taka ciekawostka – okazalo sie, ze zestaw parametrow ktory daje najbardziej stabilne wyniki nie jest najlepszym zestawem dla zadnego z testowanych rynkow (okolo 30))
@Lucky
„Niestety o samym systemie za duzo dyskutowac nie bede.”
Oczywiste 🙂
„Oczywiscie za X okres dla Y rynku najlepszy parametr to np Z, ale im dluzszy okres wezmiemy do testow, tym wiekszy zakres parametrow przynosi zyski (po odjeciu prowizji).”
Z zakresem to zgoda.NA trendowych rynkach w tzw. długim czasie jest możliwe „wyprodukować” stabilnie wyglądający system dla kilku rynków.
„okazalo sie, ze zestaw parametrow ktory daje najbardziej stabilne wyniki nie jest najlepszym zestawem dla zadnego z testowanych rynkow”
Ja to nazywam syndrom Frankenstaina 🙂
Z najlepszych części nie złożysz najlepszej całości.
@Kat
Ta ściaga z blogu autora w postaci e-boku jest OK.
W słowach czuć slady praktyka.
Taki mechaniczno-techniczny Van Tharp w pigułce.
MOżna polecić dla wszystkich którzy zaczynają z głowa w chmurach i rózowymi okularami.
Zobacz jak ważny jest czas tych kilku —nastu lat by wdrożyć coś do produkcji właściwe przetestowane, a tu żyjemy w kraju gdzie jedna decyzją administracyjna sie to niweczy.
Weź prześlij Maciejewskiemu jeden egzemplarz na biurko niech sobie dokształt zrobi , że najważniejsza jest ochrona kapitału /to co jest/, a nie potencjalne zyski /to co będzie/ 🙂
> Jak sobie poradzi bo parametry sie zmieniły na tyle ,że będę miał po roku np. 3 razy większy DD i połowę mniejszy zysk no to ja dziękuję za takie poradzenie sobie.
To jest dobre do jakiś teoretycznych rozważań na blogu , ale nie do produkcji.
Dlatego lepiej byłoby więcej uwagi poświęcić zarządzaniu pozycji,(MM) niż testowaniu coraz to nowych sygnałów buy, sell – in sample, out of sample.. Szczególnie teraz, jak ma być 20 zł za 1 pkt. Czy obecnie stosowany MM *0.5 da przybliżony wynik ? Chyba innego wyjścia nie ma.
no wlasnie to pisze pit65 ja przeteastowalem system na eurusd ktory po 18 latach dal calkiem ciekawe zyski a w tescie out-of-sample 505 pipsow przez nastepne 5 lat i taksie zastanawiam czy nie jest to wszystko tylko kwestia dopasowania parametrow do danych out i in.
@Robert:
A jak wypadlo WFO ratio? Sredni zysk dzienny w in-sample po optymalizacji do sredniego zysku w oos. Srednia tych ilorazow powinna byc bliska 1, jak wiekszy niz 1 to super, ponizej 0.5 ja bym nie uzywal.
@Jack
„Czy obecnie stosowany MM *0.5 da przybliżony wynik ?”
No właśnie przyblizony tylko tego przybliżenia nie jesteś w stanie sobie wyliczyć bo ciach za jednym zamachem i NIE.
Tak sie „profesjonalnie” zarządza rynkiem w tym kraju z 20 letnia historią.
Wszystko jest fajnie jak sobie pykasz dla sportu nieoptymalną stawka np. 1 kontraktem, ale jak masz jakiś trading plan robiony na następne kilka lat ze stawka dopasowaną do akceptowalnego ryzyka no to to przybliżenie zaczyna „kosztować” cię parę lat życia i przekłada się na niewiadomą ile odejmie z synchronizacji systemu z rynkiem.
Bo raczej nie doda, a nawet jeśli to nie jestes w stanie tego wyliczyc bez zmiany parametrów bo nie uwzgledniono ,że potrzebujesz choćby minimalnego okresu danych historycznych.
Najlepsze wyjście to dac sobie na ten czas spokój , stracić zawsze można byle nie tak głupio.
Prosta wyliczanka * 0.5 jest zbyt prosta bo zakłada ,że rynek administracyjnie się pomnoży przez dwa, bez zmiany czynników ryzyka /np zmienności, niestacjonarności/. Tu nie ma liniowej zależności i wpłynie to na rozkład notowań , a te na ew. desynchronizację systemów , której teraz nie sposób oszacowac.
@Robert
„taksie zastanawiam czy nie jest to wszystko tylko kwestia dopasowania parametrow do danych out i in.”
Skoro OS dało ci jedynie 505 to urealniło Twoje oczekiwania po IS.
Sa rózne szkoły, jedni całkowicie separuja parametry tylko trudno oczekiwać po takiej operacji by systemy działały na wszelkich mozliwych zakresach czyli prawidłowo.
Weź taką średnia. Projektujesz sys. dla szybkich ruchów, IN daje Ci przedział 2-20 i potem aby nie przoptymalizować dajesz dla OS 30-50.
Klops , a nie zuważyłeś
kompletnego rozjazdu logiki bo tracisz początkowy koncept budowy czyli szybkość i tak właściwie to jest już inny system.
Osobiście preferuję inne podejście:
Przeważnie parametry OS jest to pewien węższy podzbiór parametrów IS.
W tym sensie jest to pewien zakres wspólny dopasowania, który jest w miarę stabilny.
Ważne jest natomiast to , że parametry każde z osobna „nie widzą” OS w drugim przebiegu.To daje Ci niezbędna wiedzę czy system jest grywalny w pewnym dopuszczalnym zakresie zmian cen z przyszłości , aczkolwiek nie uciekniemy od IN w kwestii samego zakresu.
Czyli daje Ci pewną elastyczność wyboru z zakresu dla „niewidocznego” OS , a nie punktowy fitting w IN , który może byc kwestią przypadku dla testowanego okresu, a nie działającej reguły.
Elastyczność to nic innego jak róznica między parametrem wpasowanym IN i mającym pracować w bliskiej przyszłości, a najlepszym możliwym do uzyskania dla OS. Jeżeli ta różnica jest zbyt duża, czy przypadkowa system łatwo traci parametry i synchronizację daje nam wiedzę ,że parametry wskaźnika, który stosujemy są niestabilne i niegrywalne.
I to jest clue , a nie sztuczny rozdział parametrów, który niewiele więcej mówi.
Dopiero to daje pewne pojęcie i miarę niestabilności, którą można później obrabiać np. analizą MC.
Ktoś powie, ale to nie ma sensu bo dopasowanie do szerszego zakresu IN nadal istnieje.I ma istnieć . Na tym to polega by te wszystkie trybiki sie zazębiały , a nie by każdy pies był z innej wsi bo w ten sposób wracamy do gry bez systemu czyli do punktu wyjścia.
A czy cała ta zabawa in/out-sample nie powinna odpowiedzieć na pytanie, czy okresowa reoptymalizacja jest w sumie dać lepszy wynik niż optymalizacja „za całość”? Bo jeśli (dla danego systemu i zakresu danych) to nie działa to idea bieżącego dostosowywania się do rynku (z danym systemem i zakresami danych) to lipa.
@mirek
„Bo jeśli (dla danego systemu i zakresu danych) to nie działa to idea bieżącego dostosowywania się do rynku (z danym systemem i zakresami danych) to lipa.”
Oczywista oczywistość,
1.Dlatego też trudno mi się zgodzić z logika tych którzy w OS stosują zupełnie inne parametry aniżeli w IS. To nie ma prawa działać bo mierzysz rózniće z czymś co na wejściu przewaznie nie działa. Taka koniunkcja powinna zawsze dawać wynik negatywny.
2.ale podstawowa rzecz w tej zabawie to nie o dostosowanie za wszelka cenę chodzi,ale eliminacja wpasowania na próbce in sample i nie chodzi o wpasowanie stacjonarne /takie to by było wskazane 🙂 / tylko to przypadkowe dla danego okresu nie do powtórzenia w OS. Inna rzecz ,że ta eliminacja realizuje sie poprzez pewne dostosowanie /uelastycznienie/ parametrów dla pewnego częściowego okresu i poprzez to uelastycznienie jesteśmy w stanie na podstawie wyników ocenić czy parametry pozostają względnie stabilne w czasie. W pewnym sensie teoretycznie można by nawet zaakceptować overfitting byle był stabilny choć to jest przewaznie odwrotnie proporcjonalne.
3.Generalnie okresowa reoptymalizacja daje ilościowo raczej gorsze wyniki niż za całość, aczkolwiek przychodzi mi na myśl taki elastyczny instrument /wskaźnik/, który dostosowuje sie do krótszego okresu efektywniej niż do całości hurtem.
Po prostu w krótkim okresie łatwiej mu sie dostosować do kilku stanów rynku niżli do wszystkich w całości.
Ale to już specyficzne zastosowanie tej techniki nie do sprawdzania IS , ale jako pełnoprawna technika testowania i uelastycznienia wskażnika do okresów częściowych by móc poprawić wyniki całości.
Taki adaptacyjny model. To jest możliwe aczkolwiek dyskusyjne bo znając niestacjonarność rynku może się okazać ,że unikająć wpasowania w parametry daliśmy się złapać we wpasowanie w czas .
Tak więc umiar wielce wskazany. Jak zwykle.
@Kathay,Lucky
W uzupełnieniu wpisu artkuł autora o tym , że przeżywanie nie równa się zwiększaniu prawdopodobieństwa sukcesu zgodnie z tym co wcześniej napisałem:
„bo zalezność jest taka że im dłużej tym zyski przeciętnieją”
Wszystko to ma pewien optymalny balans, który nie jest stacjonarny w czasie. Cała sztuka by na tej balansowej fali surfowac i nie dać się zepchnąć pod wodę 🙂
Miło jest jak człowiek coś czyta i odnajduje swoje własne przemyślenia.
mechanicalforex.com/2013/03/the-relevance-of-back-testing-time-does-a-longer-back-test-lead-to-better-success-probabilities.html
Kathay czy testowałeś framework napisany w pythonie który autor zachwala do wspomagania testowania systemów , bo zgadzam sie z autorem , że MT4 i MT5 jest do tego jak młotek na słonia.
Mam dość napięty kalendarz tego lata , ale jak tylko znajdę chwilę wejdę w dyskusję:)
@pit65
jeszcze nie było czasu nic potestować, przeleciałem tylko szybko w pociągu ten ebook; jak będzie czas to może jakieś pomysły z niego uda się wyciągnąć i podyskutować
tak sobie mysle, jezeli testy maja polegac na dopasowaniu prametrow do danych to lepiej to zrobic do biezacego okresu i pozniej modyfikowc czyli wybrany system dziala na dziennych robie np. raz w roku test parametrow wybieram ktory mi sie podoba i dzialam nim prze rok , pozniej powtorka, byc moze nie jest to najzyskowniejsze rozwiazanie ale wydaje mi sie, ze wowczas bedzie nastepowala samomodyfikacje systemu i nie bedzie takiej sytuacji jaka mialem, ze 18 lat daje pow. 8000 pipsow a nastepne 5 lat 500, bo w takim wypadku szkoda czasu lepiej otworzyc lokate. Jak myslicie? Chyba kathay pisal o podobnym podejsciu do testowanych systemow.
ten test raz w roku na danych z poprzedniego roku , zeby nie byly zbyt duzy zbior danych ani zbyt krotki, wiecie dobrze dlaczego.
Lucky dzieckiem w kolebce kto eb urwa hydrze, 100% trafnosci systemu w okresie 20 lat ciekawie na jakiej gieldzie, czy tylko na papierze, badzmy powazni, albo nie piszmy byle czego
@copy
Bądź poważny, nie odróżniasz „100% rynkow zyskownych” od „100% trafności systemu”?